







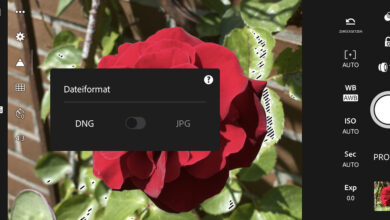
Raws in JPEG-Größe: Rawsie rechnet Raw-Daten so um, dass sie sich platzsparend archivieren lassen. Laut Produktversprechen des Rawsie-Herstellers gibt es keine Änderung des Dynamikbereichs, der Pixelauflösung oder der Bittiefe. Außerdem entstehen angeblich weder Kompressionsartefakte noch kommt es zu Farbverlusten. Und das soll funktionieren?
Praxis
Wir haben es mit einer Reihe von Raws ausprobiert, allen voran solche, die nicht nur viel Platz auf der Festplatte einnehmen, sondern auch den Workflow spürbar ausbremsen: Unkomprimierte Rohdaten aus Kameras mit hoher Auflösung. Zum Beispiel Vollformat-Files aus einer Sony a7r IV mit 61 Megapixel oder 50 Megapixel Mittelformat-Dateien aus einer Fuji GFX 50R. Beide Kameras produzieren unkomprimierte Raws mit etwa 120 Megabyte Speicherbedarf. Wer im Jahr 10.000 Bilder damit aufnimmt, braucht also allein zur Archivierung jährlich 1,2 Terabyte neuen Speicherplatz. Werden die Bilder im lokalen Netzwerk auf einem Server gespeichert, dauert der Transfer einer 32 Gigabyte-Karte mit rund 250 Aufnahmen selbst bei schnellem W-LAN rund eine Viertelstunde. Diese Ladezeiten sind natürlich auch für die spätere Raw-Bearbeitung einzurechnen.
Technik
Raw-Daten kann man verlustfrei und verlustbehaftet komprimieren. Viele Kameras reduzieren die Bildgröße schon per Vorgabe selbst um bis zu 50 Prozent. Rawsie gibt in der Werbung 80% Speicher-Sparpotenzial an. In unseren Tests konnten wir knapp 70 Prozent erreichen. Dann sind die ursprünglich 120 Megabyte raubenden Datensätze nur noch 30 bis 40 Megabyte groß – je nachdem, wieviele Details im Motiv enthalten sind. Rechnet man die Raws also in kleine DNGs um, sinkt der Speicherbedarf selbst im ungünstigen Fall von jährlich 1,2 Terabyte auf 400 Gigabyte. Das Spannendste dabei: Auch bei vielen Testbildern ist es uns nicht gelungen ein einziges zu finden, bei dem man die Kompressionsverluste hätte sehen können. Weder bei 100, 200 noch bei 400 Prozent Vergrößerung.
Zwischenfazit
Rawsie erledigt seinen Job zur vollen Zufriedenheit, was ganz besonders für Lightroom-Anwender gilt, die mit dem Tool ganze Kataloge am Stück bearbeiten können. Leider gibt es das Programm bisher nur für Apples macOS. Eine Windows-Version ist angekündigt. Ebenso wie eine Kommandozeilen-Variante für den Serverbetrieb. Rawsie kostet aktuell knapp 80 Euro pro Jahr oder 150 Euro einmalig. Wer sich auf 30 Bilder am Tag beschränkt, kann die Software kostenlos nutzen.
Aber …
Um Rawsie einzurichten, muss man standardmäßig auch den Adobe DNG Converter installieren, damit das Programm arbeiten kann. Adobes Umrechner kostet nichts, hat keine Mengengrenzen und erledigt die Aufgabe, Raws in komprimierte DNGs zu verwandeln, ebenso. Allerdings mit mehr Einstellungsoptionen, aber weniger Komfort im Zusammenspiel mit Lightroom.
Es liegt nahe auszuprobieren, wie sich die verlustbehafteten Ergebnisse des Adobe-Tools im Vergleich zu denen aus Rawsie schlagen. Das Ergebnis überrascht: Adobes Kompression ist meist effektiver. Sie liegt oftmals bei über 80 Prozent Dateneinsparung und die Ergebnisse zeigen keine sichtbaren Verluste – ebenso wie die Resultate von Rawsie. Erstaunlich: Nur stark verrauschte Dateien, die mit hohen ISO-Werten aufgenommen wurden, verlieren ein wenig Datenvolumen.
Rawsie-Test: Fazit
Wer sich ein speicheroptimiertes Raw-Archiv auf DNG-Basis zulegen will, muss bei einer selbst angelegten, komplexen Datenstruktur ziemlich viel Zeit einplanen, weil im Grunde jedes Projekt einzeln umgerechnet werden will. Das funktioniert mit Rawsie nur dann mit mehr Komfort, wenn man Lightroom zur Bildverwaltung nutzt. Interessanter wird das Produkt in Zukunft sein, sobald es auch auf Windows oder als lokaler Serverdienst zur Verfügung steht. Aber auch dann muss man sich fragen: Warum Geld bezahlen, wenn man zumindest gleichwertige Ergebnisse mit einer Freeware erhält, die man sowieso installieren muss und die mit viel mehr Kameramodellen kompatibel ist?
Am Rande bemerkt
Ich habe die Gelegenheit genutzt und mein ganzes Raw-Archiv (ab 2006) mit einem Ausgangsvolumen von 10 Terabyte vom Adobe DNG Converter herunterrechnen lassen. Die so erzeugte Kopie hat (mit nächtlichen Pausen) rund drei Tage Rechenzeit über ein 10G-Netzwerk gebraucht und ist jetzt nur noch knapp 2,5 Terabyte groß, also sehr viel handlicher. Alle Bilder passen so als „Immer-dabei-Archiv“ auf den freien Speicherplatz meines Notebooks. In den nächsten Tagen werde ich die Bilder als Backup auf eine externe SSD von Crucial kopieren. Eigentlich kein großer Akt, aber ich bin trotzdem gespannt, wie lange das dauert.



Sobald ein Algorithmus verlustbehaftet arbeitet, gehen Daten unwiederbringlich verloren. Die sind weggeschmissen. Man kann prinzipiell alle Daten komprimieren, auch datenreduzierte. Wenn ein Kamerahersteller die Raw-Fotos ohne Datenkomprimierung auf der Speicherkarte speichert, muss man an der Kompetenz zweifeln. Es gibt allerdings auch Kamerahersteller, die bereits Raw-Formate datenreduziert speichern, manchen muss man erst auf die Finger klopfen, ehe sie es zugeben. Dafür haben dann findige Marketingleute die Bezeichnung Datenkomprimierung missbräuchlich verwendet.
Kompressionsverluste darf es keine geben, denn Kompression ist per Definition nur dann gegeben, wenn Daten wiederherstellbar sind. Z.B. kann man Daten und Programme, was ja jeder schon mal gehört hat, zippen und entzippen. Bei den verlustbehafteten Reduzierungen ist es dies nicht möglich. Will man ein datenreduziertes Foto wieder herstellen gibt es, je nach Einstellung bei der Reduzierung, mehr oder noch mehr Pixel, die beim Öffnen des Bilds möglichst trickreich erfunden werden MÜSSEN, denn die ursprünglichen Pixel wurden weggeschmissen. Dass man so etwas, bei gemäßigter Anwendung bei einer 100%-Ansicht kaum oder nicht erkennt, ist eine Binsenweisheit. Eine 200%- oder 400%.Ansicht ist natürlich Unfug, denn diese erreicht man nur durch einen Vergrößerungsalgorithmus, also durch das wieder mehr oder weniger geschickte Hinzufügen von Pixeln durch einen Algorithmus. Bei 200% müssen aus jedem Pixel 4 Pixel gemacht werden, bei 400% schon 16 Pixel. Deshalb ist ja bekanntlich auch eine Schärfenbeurteilung nur bei einer 100%-Ansicht sinnvoll.
Wenn jemanden die Dateigröße pro Foto zu groß ist, sollte eine Kamera mit geringerer Auflösung verwenden. Wozu mit hoher Auflösung fotografieren, wenn dann ohnehin ein guter Teil der Bildqualität vernichtet wird?
Die Speicherkapazität von Datenträgern ist so groß und die Kosten von Festplatten so niedrig, dass diese Gründe wegfallen.
Dass die Datenübertragung von externen Geräten in eine Computer und auch die Datenübertragung innerhalb eines Computers nicht berauschend ist, weiß man ja. Dafür kosten diese Dinger auch fast nichts mehr. Computer sind konzeptionell richtige Täuscher, denn es werden durch kleine, wirklich schnelle Bauteile, meist Cache genannt, Geschwindigkeiten bei kleinen Datenmengen erreicht, die bei größeren Datenmengen nicht erreichbar sind und beim Datentransfer zu langen Wartezeiten führen. Hat man dann auch noch ein gar so bequemes WLAN, wird der Datentransfer auch nicht eben schneller.
Nun, was das Kopieren auf eine SSD zur Sicherung anbelangt, so dauern das bei 2,5 TB gleich lange, egal, ob Fotos komprimiert, unkomprimiert, datenreduziert oder sonst was sind. Es dauert auch gleich lange, wenn 2,5 TB Musik oder Videos kopiert werden. Kleine zeitliche Unterschiede kann es bei der Anzahl und der Einzelgröße der Dateien geben. Doch ob der Spaß 6, 8 oder 10 Stunden dauert, ist ziemlich gleichgültig, das System ist dabei ordentlich beschäftigt.
Bei Kompressionsverfahren unterscheidet man zwischen verlustfreien Verfahren wie LZW und verlustbehafteten Verfahren wie JPEG. Verlustfreie Kompressionsverfahren können lediglich die Redundanz in den Bilddaten ausnutzen, aber bei typischen Fotos ist diese gering; eine Reduktion der Dateigröße auf weniger als die Hälfte ist nur in Ausnahmefällen möglich. Insbesondere verrauschte Aufnahmen mit höheren ISO-Werten lassen sich nur wenig komprimieren, da Rauschen seiner Natur nach eine geringe Redundanz hat.
Verlustbehaftete Verfahren wie JPEG basieren auf einem Modell der visuellen Wahrnehmung und versuchen, vor allem solche Elemente eines Bildes wegzulassen, deren Fehlen nicht oder kaum auffällt. Dazu werden die Bilddaten beispielsweise beim JPEG-Verfahren von der Ortsdomäne (also die Farben der Pixel) in die Frequenzdomäne umgewandelt (die Anteile verschiedener Ortsfrequenzen in 8 mal 8 Pixel großen Kacheln, in die das Bild zerlegt wird), und dann der Anteil von visuell weniger wichtigen Ortsfrequenzen weniger präzise beschrieben. Im Ergebnis enthalten die Anteile der verschiedenen Ortsfrequenzen nach dieser Vergröberung dann mehr Redundanz und lassen sich kompakter als die ursprünglichen Pixeldaten speichern. Schon mit dem fast 30 Jahre alten JPEG-Verfahren, gelang es, typische Fotos auf 1/5 bis 1/10 der ursprünglichen Dateigröße zu verkleinern, ohne dass es einen sichtbaren Qualitätsverlust gibt – man muss die Bilder schon bei 100 Prozent oder mehr vergleichen, um Unterschiede zu sehen. Erst bei deutlich höheren Kompressionsfaktoren fallen die typischen JPEG-Artefakte wie eine sichtbare Kachelstruktur, Säume und Doppelkonturen störend auf.
Bei Raw-Dateien ist eine verlustbehaftete Komprimierung ohne visuell auffällige Verluste schwieriger, denn die Wahrnehmungsmodelle, wie sie die Grundlage von JPEG etc. bilden, lassen sich nicht direkt anwenden – Raw-Daten sind ja noch keine Bilder. Leider verraten die Entwickler von Rawsie nicht, wie sie dieses Problem gelöst haben.
Dass eine Kompression von Raw-Dateien heute dankbar angenommen wird, liegt natürlich an den immer höheren Sensorauflösungen. Die Speicherkapazität ist dabei nicht einmal der wichtigste Faktor, denn die Kapazität gängiger Speichermedien steigt noch deutlich schneller als die Sensorauflösung. Das größere Problem ist die Zeit, die der Datentransport benötigt, sei es von einer Festplatte auf die andere – möglicherweise nicht über eine schnelle Ethernet- oder WLAN-Verbindung, sondern über den viel langsameren Internetzugang, wenn man in die oder aus der Cloud kopiert – oder auch von der Platte in den Hauptspeicher, wenn man eine Datei öffnet. Da kann es zu einer merklich besseren Performanz führen, wenn erst eine kleinere, komprimierte Datei geladen und diese dann im Hauptspeicher entpackt wird. So lange eine verlustbehaftete Komprimierung der Raw-Daten nicht die Eigenschaften sabotiert, wegen derer man überhaupt mit Rohdaten arbeitet, kann mit den Verlusten vermutlich leben. Ein verlustbehaftet komprimiertes Bild aus einer hochauflösenden Kamera kann unvergleichlich mehr Details zeigen als ein lediglich verlustfrei komprimiertes Bild aus einer Kamera mit entsprechend niedrigerer Auflösung, das dieselbe Dateigröße hat.
Wohlgemerkt: Die unkomprimierten Originaldateien wirft man ja nicht weg. Wenn man ein Bild noch einmal mit der höchstmöglichen Qualität entwickeln will, überträgt man einfach die Entwicklungseinstellungen auf die Originaldatei und exportiert deren entwickelte Version.
„Bei Kompressionsverfahren unterscheidet man zwischen verlustfreien Verfahren wie LZW und verlustbehafteten Verfahren wie JPEG.“
Genau das ist der Fehler! Kompression ist per Definition IMMER VERLUSTFREI. Wenn nun irgendwelche unwissende, meist Marketingleute die Begriffe wie „Datenreduktion“ usw. nicht verwenden wollen, weil sie damit implizit zugeben, dass das erhaltene Produkt qualitativ schlechter wird, missbrauchen sie diese Bezeichnung.
Nochmals, man kann datenriduzierte Inhalte komprimieren, MUSS sie aber nicht. Natürlich macht man es, doch sind Datenreduzierung und Komprimierung unabhängig voneinander.
Jede andere Behauptung ist falsch. Darüber kann man nicht diskutieren und keinen Kompromiss finden. Tut mir leid, auch wenn es sehr beliebt ist.
Die Quelle dieser „per Definition IMMER VERLUSTFREI“ für Komprerssion würde ich gerne mal erfahren.
Ich habe mich jetzt der Einfachheit halber mal auf Wikipedia bezogen (und habe Kompressionsverfahren für Psychologie, Signalverarbeitung, etc. mal weggelassen):
Man spricht von verlustfreier Kompression, verlustfreier Kodierung oder Redundanzreduktion, wenn aus den komprimierten Daten wieder exakt die Originaldaten gewonnen werden können. Das ist beispielsweise bei der Kompression ausführbarer Programmdateien notwendig.
Bei der verlustbehafteten Kompression oder Irrelevanzreduktion können die Originaldaten aus den komprimierten Daten meist nicht mehr exakt zurückgewonnen werden, das heißt, ein Teil der Information geht verloren; die Algorithmen versuchen, möglichst nur „unwichtige“ Informationen wegzulassen. Solche Verfahren werden häufig zur Bild- oder Videokompression und Audiodatenkompression eingesetzt.
Kompression heißt „zusammengedrückt“. Von verlustfrei oder nicht haben die Römer, von denen der Begriff stammt, nichts aufgeschrieben.
Daher würde mich auch interessieren, wo „immer verlustfrei per definitionem“ herkommt. Denn die Definierer des Begriffs haben das anscheinend nicht definiert. 😉
Glückauf, Ollie
Wenn ich das als Informatiker noch mal einwerfen darf:
Die Begriffe „Kompression“ und „Datenreduktion“ sind keine Gegensätze, sondern bedeuten dasselbe. Der Zweck der Kompression besteht ja darin, die Datenmenge zu reduzieren.
Wenn man den Unterschied zwischen verlustfreier und verlustbehafteter Kompression beschreiben will, muss man sich auf die enthaltene Information beziehen. Eine verlustfreie Kompression reduziert die Datenmenge, lässt die enthaltene Information jedoch unangetastet. Deshalb funktioniert ein solches Verfahren nur, wenn die ursprünglichen Daten redundant sind.
Eine verlustbehaftete Kompression reduziert dagegen auch die enthaltene Information, die sich dann nicht mehr vollständig rekonstruieren lässt. Das führt dennoch zu befriedigenden Ergebnissen, so lange das Kompressionsverfahren nur weniger wichtige Informationen weglässt.
Ein verlustfreies Kompressionsverfahren kann mit beliebigen Daten arbeiten, ganz unabhängig davon, wofür diese Daten stehen, welche Information sie also enthalten. Texte, Bilder, Videos, Audiodateien oder beliebige andere Daten lassen sich mit denselben Algorithmen komprimieren – mit LZW oder ZIP beispielsweise.
Verlustbehaftete Verfahren werden dagegen jeweils für bestimmte Inhalte entwickelt. So beruht JPEG auf einem Modell der visuellen Wahrnehmung und MP3 auf einem Modell der akustischen Wahrnehmung, aus denen sich ergibt, welche Details eines Bildes beziehungsweise welche Frequenzbereiche eines Tons weggelassen werden können, ohne dass deren Fehlen störend auffällt.
Verlustfreie Kompression ist eine genauso redundante Formulierung wie gefrorenes Eis.
Das ist das Killer-Argument: „ohne dass deren Fehlen störend auffällt.“
Und was spricht dagegen, dass man, wenn die Datenmenge zu groß ist, geringe Auflösungen verwendet???????
Auf die wirklich stichhaltigen Argumente geht natürlich niemand ein, es wird nur lang und breit wiederholt, was ohnehin dauernd ausgebreitet wird.
Du hast ja selber nicht die an Dich gestellten Fragen beantwortet. Stattdessen kommst du mit Ablenkungsmanövern. Schwach!