


Virtuelle Schärfentiefe
Die Schärfentiefe war noch nie ein einfaches Konzept, und die Probleme fingen schon mit dem ewigen Streit darüber an, ob es denn nun „Schärfentiefe“ oder „Tiefenschärfe“ heißt. Heutzutage wird die vermeintliche, virtuelle Schärfentiefe immer häufiger erst in der Nachbearbeitung produziert und je nach den Anforderungen verringert oder erweitert.
Um das gleich klarzustellen: Es heißt „Schärfentiefe“ (die Tiefe oder Ausdehnung der Schärfenzone), nicht „Tiefenschärfe“ (die Schärfe in der Tiefe, also im Hintergrund). Früher war das eine klare Sache, denn aus Brennweite, Blende, Entfernung und Bildformat ergibt sich die Ausdehnung der Zone, in der die Kamera hinreichend scharf abbildet. Diverse Schärfentiefenrechner (hier ist meiner) machen es recht einfach, diese Schärfentiefe zu berechnen. Heutzutage ist der Eindruck von Schärfentiefe aber oft das Ergebnis einer Simulation.
Eine scheinbare Verkleinerung der Schärfentiefe durch eine Weichzeichnung des Hintergrunds kennen wir schon. Aktuelle Smartphone-Kameras nutzen zwei nebeneinanderliegende Kameramodule, um auf Basis des Parallaxeffekts eine Tiefen-Map zu erstellen. Abhängig von der Entfernung wird das Bild dann weichgezeichnet. Google hat nun aber eine Methode entwickelt, einen solchen virtuellen Schärfentiefeneffekt auch dann zu verwirklichen, wenn nur ein Kameramodul zur Verfügung steht.
Dazu ist ein Dual-Pixel-Sensor nötig, bei dem unter jeder Mikrolinse zwei nebeneinander liegende Pixel liegen. Solche Sensoren ermöglichen einen Phasendetektions-AF, denn die beiden Pixel schauen jeweils durch die linke beziehungsweise rechte Hälfte des Objektivs (oder durch die obere beziehungsweise untere Hälfte, falls man die Kamera hochkant hält), so dass die Bilder, die die einen und die anderen Pixel erzeugen, gegeneinander verschoben sind. Aus dieser Phasenverschiebung lässt sich berechnen, wie weit der Fokus verschoben werden muss, um auf das Motiv scharfzustellen. Zur eigentlichen Bildberechnung nach erfolgreicher Fokussierung werden die Signale der beiden Sensorpixel unter jeder Mikrolinse dann jeweils addiert.
Die beiden Bilder, die aus den rechten beziehungsweise linken Sensorpixeln entstehen, sind also Stereobilder, aus denen sich wie bei dualen Kameramodulen eine Tiefen-Map zur Erzeugung einer simulierten Schärfentiefe berechnen lässt. Darauf beruht Googles Ansatz, nur dass sie zusätzlich auf die Erkennung von Gesichtern und damit von Personen setzen.

Falls Personen im Bild erkannt werden, nimmt Googles Verfahren an, dass diese scharf abgebildet werden sollen. Der Hintergrund wird dann weichgezeichnet, wobei der Grad der Weichzeichnung von der Entfernung abhängt, die sich aus der Tiefen-Map ergibt. Nur wenn es gar keine Personen im Bild zu geben scheint, wird allein mit der Tiefen-Map gearbeitet.

Damit aber das ganze Motiv scharf abgebildet wird, simuliert Googles Verfahren eine ausgedehnte Schärfenzone: Die Schärfe fällt nicht gleichmäßig zu Vorder- und Hintergrund hin ab, sondern ist in einem gewissen Bereich konstant.
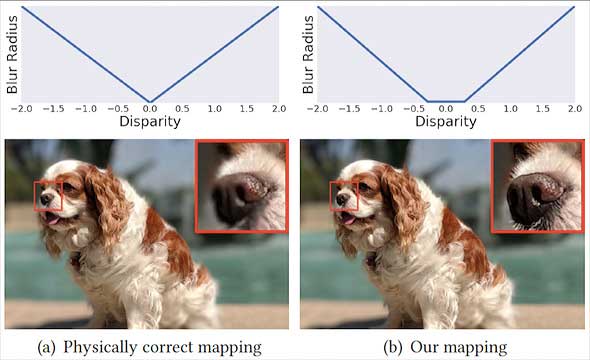
Das Verfahren ist allerdings noch nicht ganz fehlerfrei. So kann es passieren, dass ein Gesicht unerkannt bleibt und dann weichgezeichnet wird. Im folgenden Beispiel sind Mutter und Vater scharf abgebildet, nicht jedoch das von der Gesichtserkennung ignorierte Kind, das die Mutter auf dem Arm hält.

Google will sein Verfahren zur Bokeh-Simulation für Smartphone-Kameras nutzen, aber die dafür nötigen Dual-Pixel-Sensoren gibt es mittlerweile auch in vielen Canon-DSLRs. Die Präzision der Tiefen-Map hängt von der Basisbreite der Stereobilder ab, die wiederum der Eintrittspupille des Objektivs entspricht. Bei den Kameramodulen, mit denen Google arbeitet, liegt diese bei rund einem Millimeter, kann aber bei Objektiven von DSLRs deutlich größer sein. Damit wären folglich noch deutlich bessere Ergebnisse möglich. Canon hat die Dual-Pixel-Technologie bereits ausgenutzt, um die Lage der Schärfenebene bei Bedarf noch im Nachhinein zu verschieben, aber auch eine virtuelle Schärfentiefe ließe sich so realisieren.
Eine bloße Verstärkung der Hintergrundunschärfe wäre weniger nützlich, denn dazu könnte man mit besseren Ergebnissen ein lichtstarkes Objektiv einsetzen, das die gewünschte geringe Schärfentiefe schon von Natur aus produziert, wenn man es offenblendig einsetzt. Interessanter wäre allerdings Googles Technik der Vergrößerung der Schärfentiefe. Eine scharfe Abbildung des ganzen Motivs, das vor einem völlig unscharfen Hintergrund freigestellt ist, lässt sich oft nur durch Focus-Stacking erreichen, also durch die Verrechnung mehrerer Aufnahmen mit unterschiedlichem Fokus. Mit Googles Verfahren wäre dagegen nur eine einzige Aufnahme nötig.





Zwei Bemerkungen:
Der verlinkte Schärfentiefenrechner hat leider den Nachteil, dass er nur die Auswahl der Schärfenanforderung nach Unschärfenkreisen bietet, bei Sensoren jedoch eigentlich der Pixeldurchmesser sinnvoller ist.
Die virtuellen Unschärfen können qualitativ nie die optischen durch Ende des Schärfentiefenbereichs eines Objektivs erreichen. Auch dann nicht, wenn die zunehmende Entfernung und damit zunehmende Unschärfe versucht wird zu simulieren, was bei dem Beispielbild mit dem unscharfen Kind in der Mitte ohnehin nicht mal versucht wird. Immerhin ist das blaue Leibchen des Kinds in der selben Schärfenebene wie das Kleid der Frau, jedoch genauso verschwommen wie das Fenster im Hintergrund. Ziemlich unglaubwürdig.