Die (fotorealistische) Zukunft der Kommunikation?
Vielleicht erinnern Sie sich noch an die Vorstellung der lächerlich-kruden Avatare für das Metaverse. Das genaue Gegenteil davon sind jetzt die von Metas Codec Avatars Lab vorgestellten „Relightable Gaussian Codec Avatars“. Diese Echtzeit-Repräsentationen von Gesichtern könnten nun tatsächlich die Zukunft der Kommunikation zeigen.

Relightable Gaussian Codec Avatars = Telepräsenzen
Ein Running Gag bei Videokonferenzen ist, dass die Teilnehmer in Unterhosen teilnehmen und nur im für die Webcam sichtbaren Ausschnitt formelle Kleidung tragen. Für Telekonferenzen per Webcam muss man zwar nicht mehr aus dem Haus gehen, aber hübsch machen muss man sich doch noch ein wenig. Telepräsenzen, kurz: Avatare, würden das überflüssig machen – und auch ein von der Realität abweichendes Aussehen ermöglichen.
Das vom Meta-Konzern propagierte Meta-Verse würde Menschen aus aller Welt in einer virtuellen Umgebung zusammenbringen. Avatare wären dabei virtuelle schwebende Oberkörper als Repräsentationen der Teilnehmer. Was Meta und Chef Mark Zuckerberg als erste Variante präsentierten, wurde als völlig aus der Zeit gefallen belächelt und jeder fragte sich, was man damit wohl anfangen solle (mehr Informationen, Englisch).

Relightable Gaussian Codec Avatars
Heute bin ich über ein Forschungs-Paper des Codec Avatars Lab von Meta gestolpert (Link, Englisch), bei dem mir die Kinnlade herunterfiel, nachdem ich verstanden hatte, was ich dort sah.

Was ich zunächst für die Referenzvideos echter Darsteller hielt, waren bereits die generierten Avatare. Sie müssen sich die Videos anschauen, um deren Wirkung beurteilen zu können. Man muss schon genau hinschauen, um die Unterschiede zu echtem Videomaterial zu sehen.
Gaussian Splatting – ohne 3D-Drahtgittermodell zu Relightable Gaussian Codec Avatars
Anders als früher musste hier kein aufwendiges 3D-Modell erzeugt werden, das dann texturiert, animiert und beleuchtet wird. Die hier verwendete „Gaussian Splatting“-Technik ähnelt den technisch verwandten „neural radiance fields“ (Nerfs), kann im Gegensatz zu diesen jedoch in Echtzeit berechnet werden. Stark vereinfacht handelt es sich um eine dreidimensionale Repräsentation einer Szene, die mit Deep-Learning-Algorithmen aus wenigen zweidimensionalen Fotos erzeugt wurde.
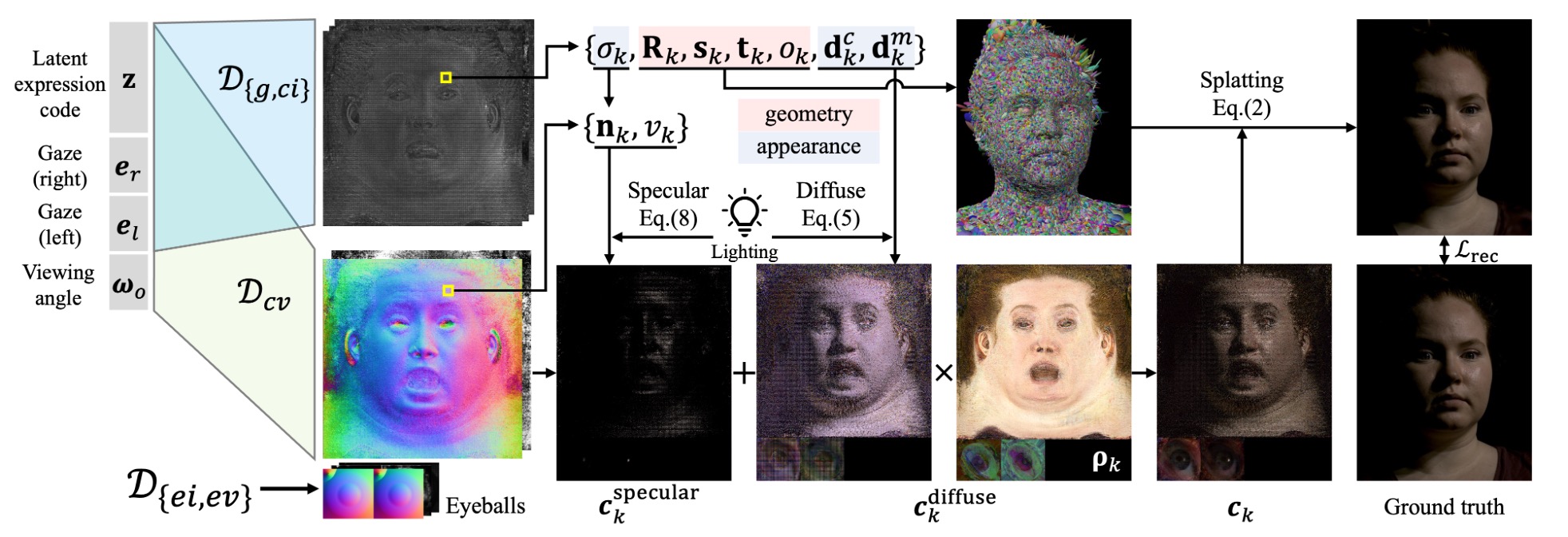
Statt eines (zeit-)aufwendigen und detaillierten 3D-Scans bedarf es so nur einiger Fotos für eine fotorealistische Telepräsenz. Und das ist natürlich spannend, da so jeder mit einem Smartphone in die Lage versetzt wird, einen solchen Avatar von sich zu erzeugen.
Im Hinblick auf die Verwendung von VR-Headsets wie der Meta-Quest ist natürlich auch die relativ geringe erforderliche Rechenleistung von Vorteil. Zusammen mit der Augen und Gesichtserkennung dieser Geräte kann die Mimik verzögerungsfrei auf den Avatar übertragen werden.
Unabhängige Parameter und hochpräzise Beleuchtung der Relightable Gaussian Codec Avatars
Das vorgestellte Gauß-Splatting erlaubt eine extrem realistische Beleuchtung der Avatare – selbst feinste Details wie einzelne Haarsträhnen und Poren werden realistisch wiedergegeben und reagieren auf wechselnde Lichtverhältnisse.
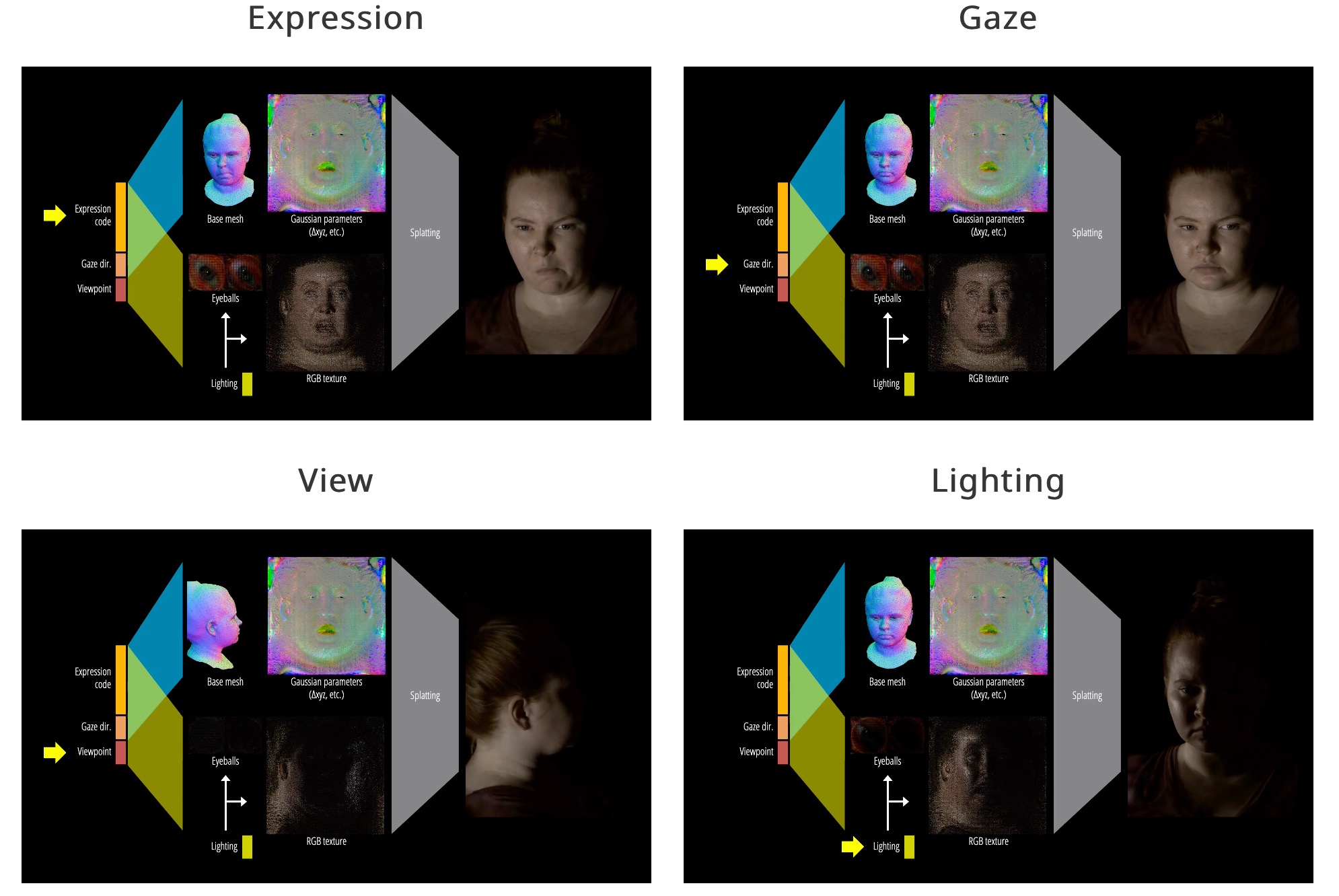

Die Forscher demonstrieren die Machbarkeit ihres Ansatzes mit einem Standard-PC-VR-Headset aus verschiedenen Blickwinkeln, mit unterschiedlichen Beleuchtungsarten. Das folgende Video zeigt die für Kommunikation entwickelte Technologie in Aktion.
Weitere Informationen und Videos finden Sie auf der Website des Forschungsprojekts: https://shunsukesaito.github.io/rgca/
Im DOCMAshop finden Sie alle Infos zum aktuellen Heft: Das ausführliche Inhaltsverzeichnis sowie einige Seiten als Kostprobe.